Project Report
Table of Contents
- Nose Tip Detection
- Full Facial Keypoints Detection
- Data Preprocessing
- ResNet-18 Model
- Results
- Shift-Invariant ResNet-18 Model *
Introduction
In this project we'll explore automatic facial keypoint detection! We will use deep convolutional neural networks to automatically detect facial keypoints to get rid of all the annoying clicking we had to deal with in the last project on image morphing! Let's start by studying fake news CNN.
Convolutional Neural Networks
Convolutional Neural Networks are very similar to ordinary Neural Networks they are made up of neurons that have learnable weights and biases. Each neuron receives some inputs, performs a dot product and optionally follows it with a non-linearity. The whole network still expresses a single differentiable score function: from the raw image pixels on one end to class/regression scores scores at the other. And they still have a loss function (e.g. MSE) on the last (fully-connected) layer that is used to 'train' the network through backpropogation (I'll spare you from the ugly multivariable vector calculus here.)
ConvNet architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties (Ex. spatial relationships) into the architecture. These then make the forward function more efficient to implement and vastly reduce the amount of parameters in the network. 1.
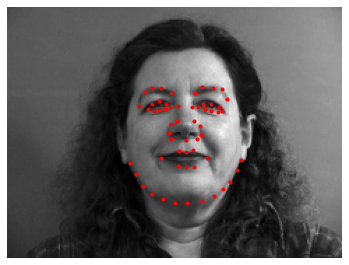
IMM Face Database
For this part, we will use the IMM Face Database for training our initial toy models. The dataset has 240 facial images of 40 persons and each person has 6 facial images in different viewpoints. All images are annotated with 58 facial keypoints. We will all 6 images of the first 32 persons (index 1-32) as the training set (total 32 x 6 = 192 images) and the images of the remaining 8 persons (index 33-40) (8 * 6 = 48 images) as the validation set.
1. Nose Tip Detection
Data Preprocessing
We will cast the nose detection problem as a pixel coordinate regression problem, where the input is a single grayscale image, and the outputs are the nose tip positions (x, y). The position (x, y) will be represented as the ratio of image width and height, ranging from 0 to 1. We first convert the image into grayscale and convert image pixel values in uint8 from 0 to 255, to normalized float values in range -0.5 to 0.5 image.astype(np.float32) / 255 - 0.5. After that, we resize the image into smaller size, 80x60. That's all the data preprocessing we do for nose tip detection on the IMM Dataset.


The Model
For the convnet, I played around with some hyperparameters and settled with a network with 3 convolutional layers, 2 max-pool layers, and 2 fully connected layers. I used mean squared error loss as the prediction loss and trained the network using the Adam optimizer with a learning rate found using hyperparameter optimization. Here's the exact CNN architecture I worked with for nose tip detection.
| Layer | Input Shape | Parameters | Total Parameters | |
|---|---|---|---|---|
| 1 | Conv2d-1 | [1, 1, 80, 60] | 312 | 312 |
| 2 | ReLU-2 | [1, 12, 76, 56] | 0 | 0 |
| 3 | Conv2d-3 | [1, 12, 76, 56] | 4816 | 4816 |
| 4 | ReLU-4 | [1, 16, 72, 52] | 0 | 0 |
| 5 | MaxPool2d-5 | [1, 16, 72, 52] | 0 | 0 |
| 6 | Conv2d-6 | [1, 16, 36, 26] | 2320 | 2320 |
| 7 | ReLU-7 | [1, 16, 34, 24] | 0 | 0 |
| 8 | MaxPool2d-8 | [1, 16, 34, 24] | 0 | 0 |
| 9 | Linear-9 | [1, 3264] | 653000 | 653000 |
| 10 | ReLU-10 | [1, 200] | 0 | 0 |
| 11 | Linear-11 | [1, 200] | 402 | 402 |
I used a random search over logarithmic scale [0.0001, 0.01) to find a suitable learning rate. I then trained model for 25 epochs using a fixed random seed with each learning rate. I found that learning rates ~1e-3 gave the best results and that running for more epochs led to overfitting for my model architecture.
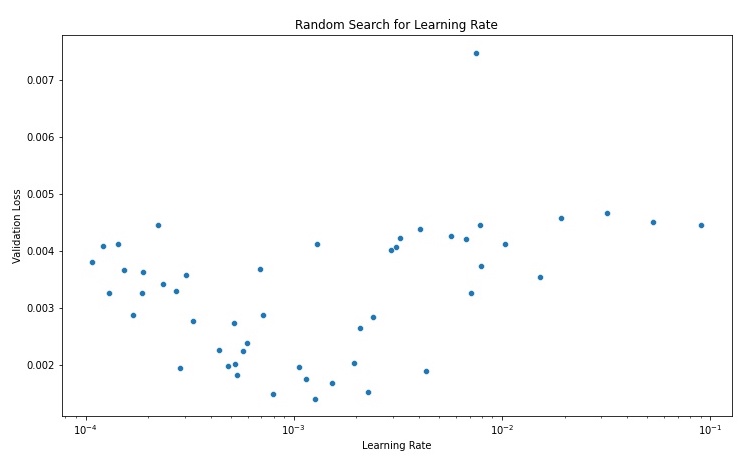
Now, I trained the network for 30 epochs using the best learning rate from above.
Time to run the network on the validation set and see the results!

Just eyeballing the results, it looks like the model performs fairly well on most pictures! It seems to perform the worst on pictures of a bald man facing at an angle. One possible explanation for this performance is that the training set didn't include similar pictures so the model never learned how to accurately predict this. The dataset is imbalanced as well as most of the pictures are people facing the front which can cause the model to perform poorly on images of people with their heads turned.
Tl;dr I blame the dataset, not the model. model good.
2. Full Facial Keypoints Detection
Data Preprocessing
For full facial keypoint detection, we'll build on top of the preprocessing pipeline we had for nose-tip detection and increase image input size to (240, 180). Since it is a small dataset, we will need data augmentation to prevent the trained model from overfitting. I increased the size of the training set to 3x the original size through data augmentation. I randomly picked 3-5 data augmentors (from Random Horizontal Flip, Random Rotation, Brightness/Contrast Jitter, Random Shift, and Random Noise) twice and then applied them to all the images in the dataset increasing the size of the training set and improving the robustness of the model.





The Model
After trying out a couple different architectures, I settled on a convnet with 5 convolutional layers, 2 fully connected layers, and 4 Max Pool layers. I used mean squared error loss as the prediction loss and trained the network using the Adam optimizer with a learning rate of 1e-3. Here's the exact CNN architecture I worked with for facial keypoint detection.
| Layer | Input Shape | Parameters | Total Parameters | |
|---|---|---|---|---|
| 1 | Conv2d-1 | [1, 1, 240, 180] | 1,600 | 1,600 |
| 2 | ReLU-2 | [1, 32, 234, 174] | 0 | 0 |
| 3 | Conv2d-3 | [1, 32, 234, 174] | 100,416 | 100,416 |
| 4 | ReLU-4 | [1, 64, 228, 168] | 0 | 0 |
| 5 | MaxPool2d-5 | [1, 64, 228, 168] | 0 | 0 |
| 6 | Conv2d-6 | [1, 64, 114, 84] | 51,232 | 51,232 |
| 7 | ReLU-7 | [1, 32, 110, 80] | 0 | 0 |
| 8 | MaxPool2d-8 | [1, 32, 110, 80] | 0 | 0 |
| 9 | Conv2d-9 | [1, 32, 55, 40] | 12,816 | 12,816 |
| 10 | ReLU-10 | [1, 16, 51, 36] | 0 | 0 |
| 11 | MaxPool2d-11 | [1, 16, 51, 36] | 0 | 0 |
| 12 | Conv2d-12 | [1, 16, 25, 18] | 2,320 | 2,320 |
| 13 | ReLU-13 | [1, 16, 23, 16] | 0 | 0 |
| 14 | MaxPool2d-14 | [1, 16, 23, 16] | 0 | 0 |
| 15 | Linear-15 | [1, 1408] | 281,800 | 281,800 |
| 16 | ReLU-16 | [1, 200] | 0 | 0 |
| 17 | Linear-17 | [1, 200] | 23,316 | 23,316 |
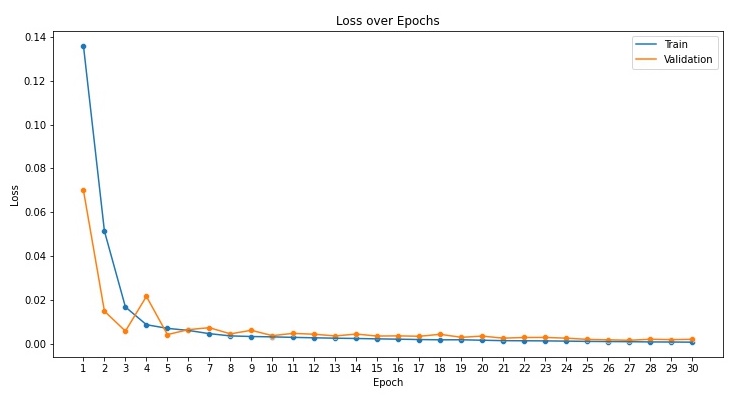
I trained this model for 100 epochs and found that it had not overfit (see plot below) and it gave pretty nice results too! There's also the visualization of the kernels of each convolution layer. This visualization in a way tells us what the network is looking at to figure out where to place the keypoints on the face. While these particular kernels aren't as intuitive as I was hoping they would be, this was still an interesting exercise.
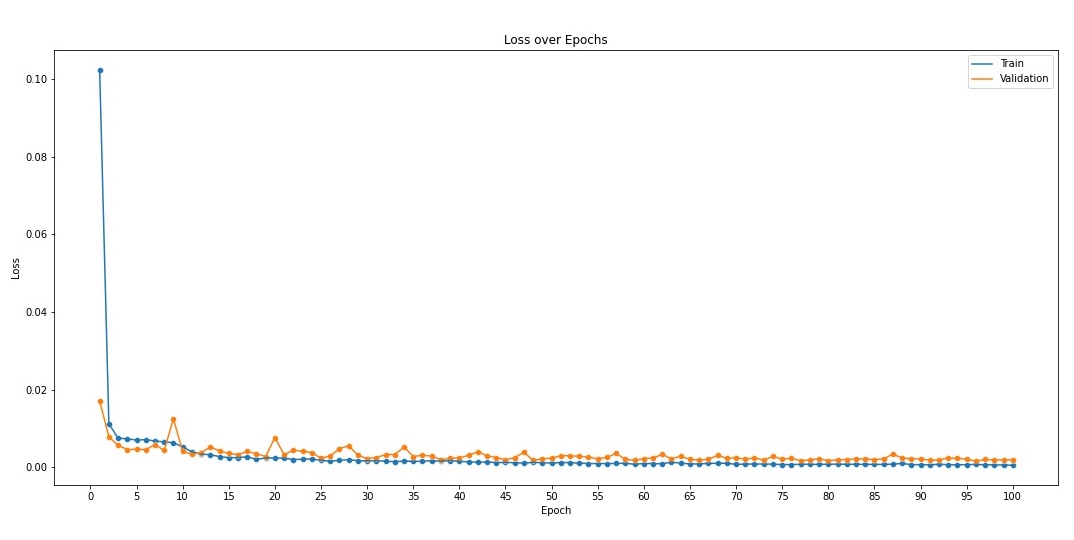

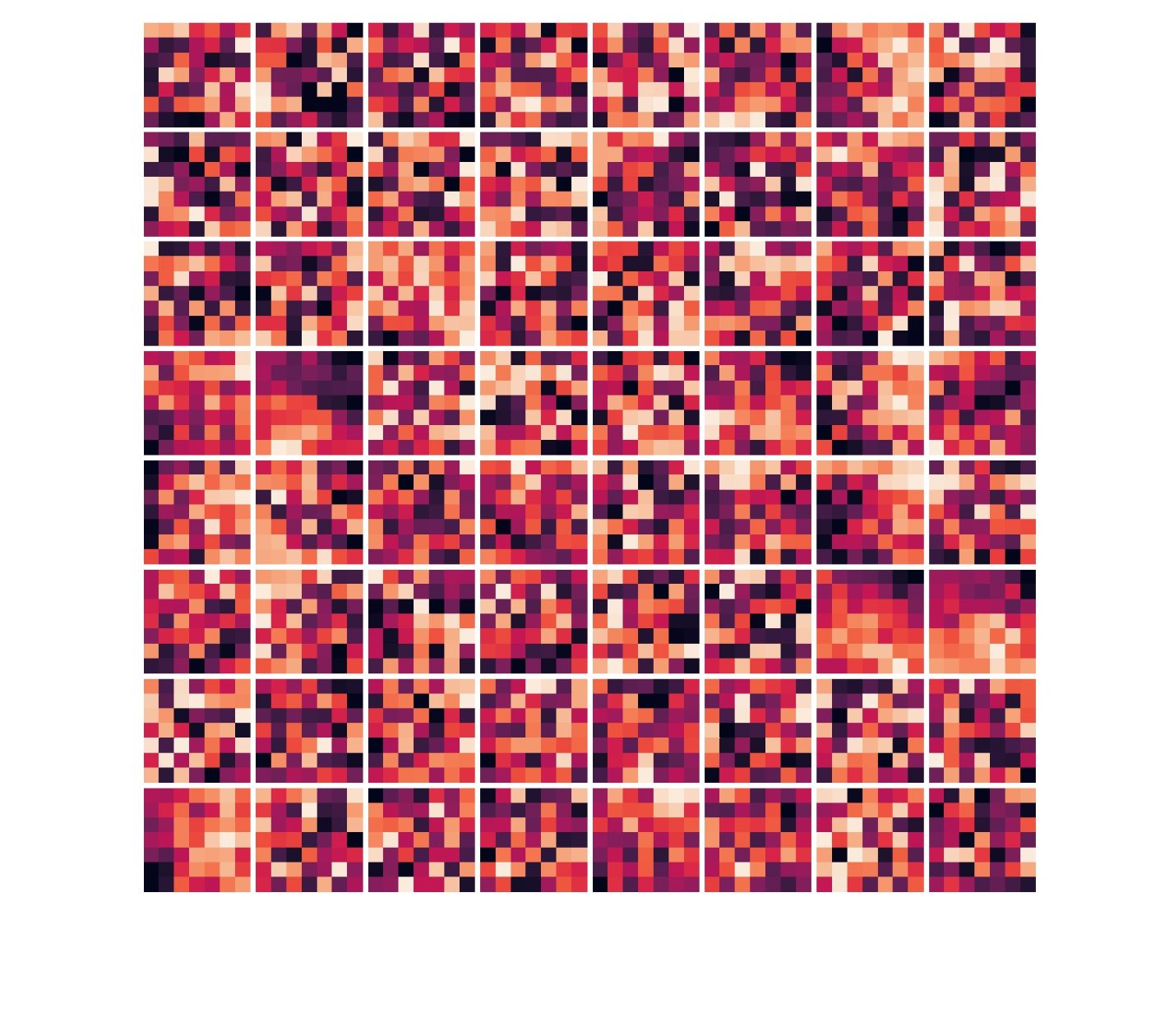

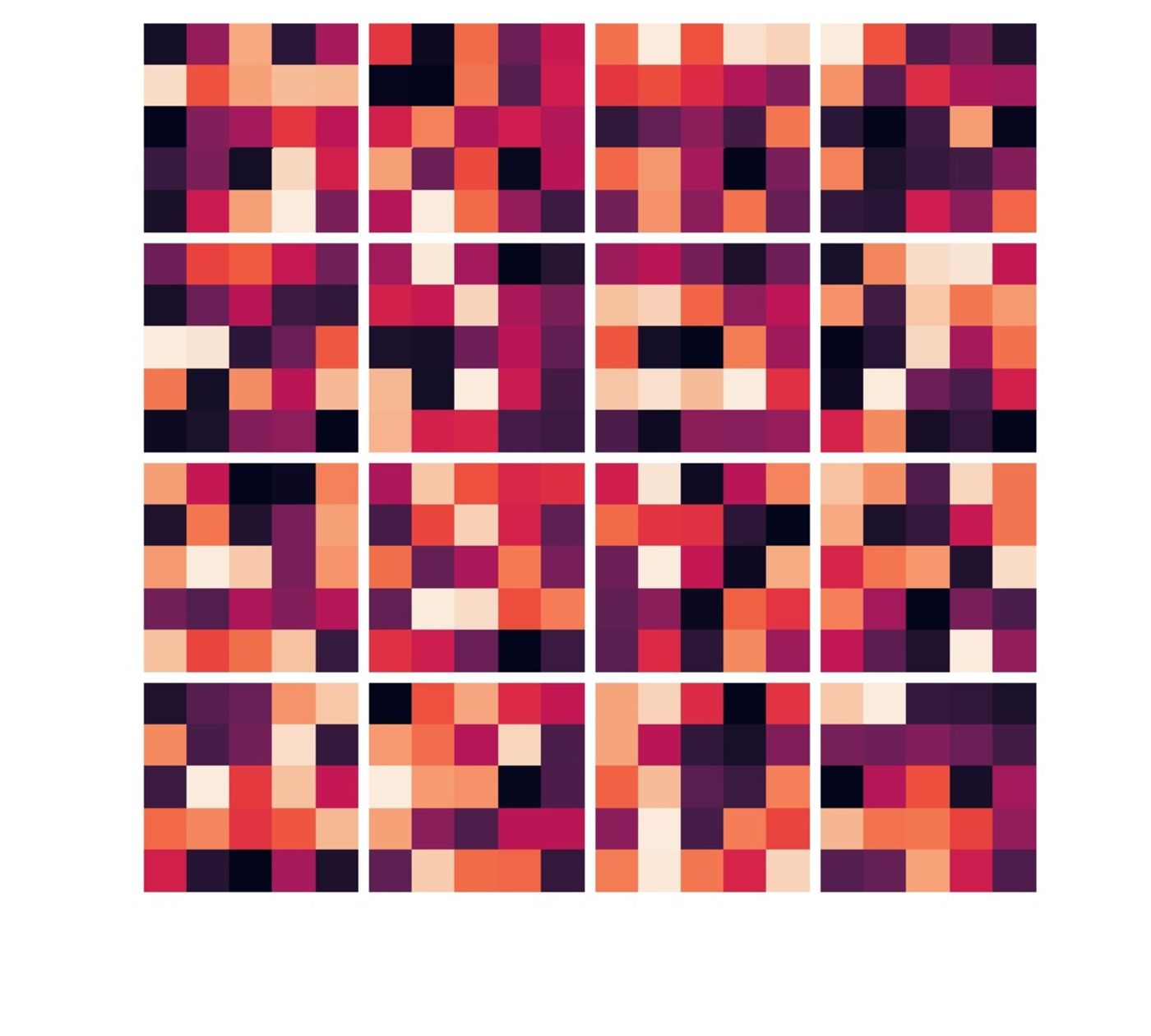
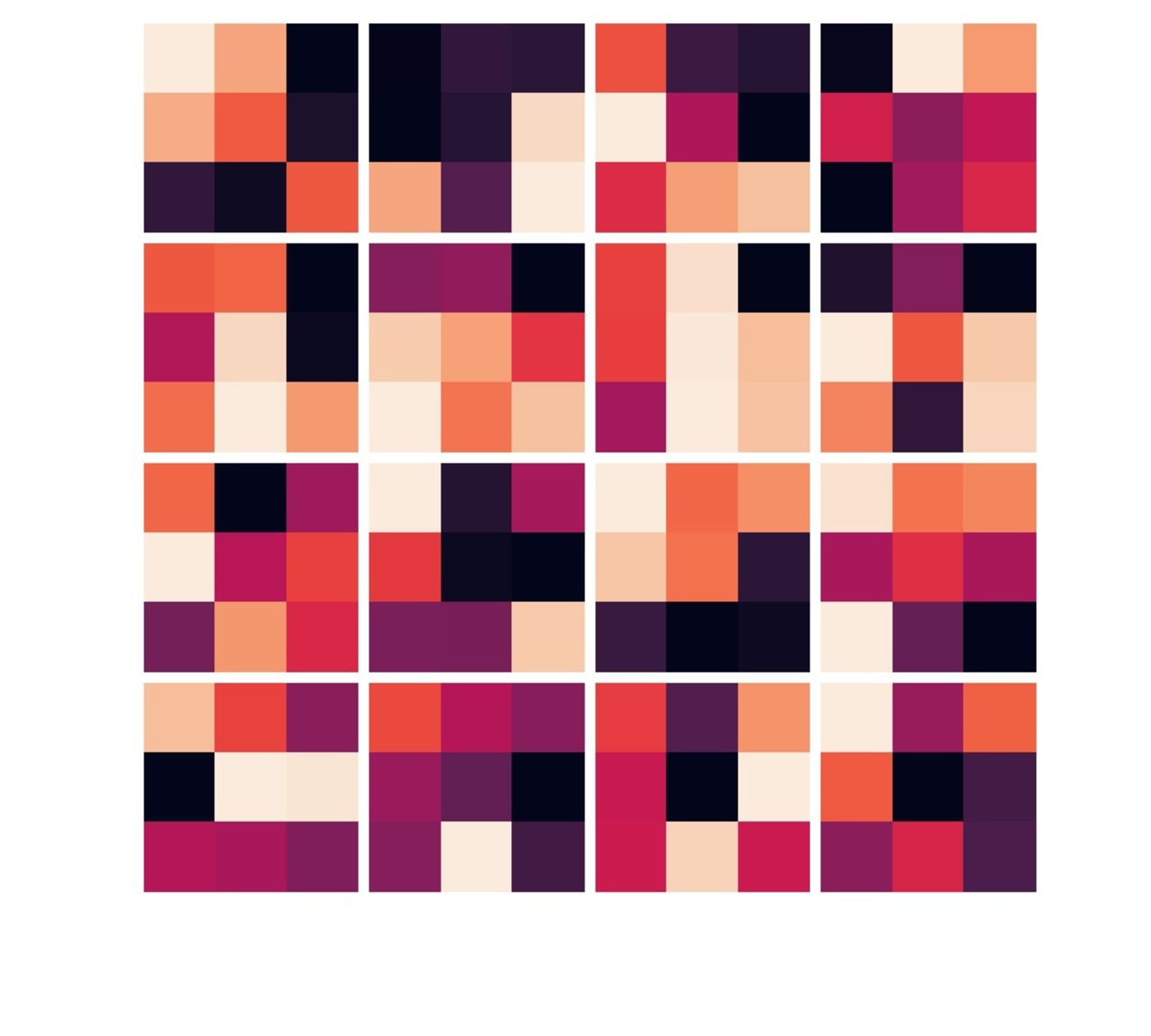
Time to run the trained convnet on the validation set and see the results!

Again, the model seems to do a fairly good job on most images. Interestingly, there's a clear pattern in the images it doesn't do as well on. The worst results are for the person with long messy hair followed by the bald person. There's also a single image of a woman with bad predictions; I believe that one's because she has her hands in the image while the other pictures only have faces. I believe the root cause for most of the bad predictions is just dataset imbalance. We just didn't see enough diverse data during training to prepare for Jazz hands.
iBUG's Faces In-the-Wild Dataset
Now we will move to a much larger dataset for training a facial keypoints detector – iBUG's Faces In-the-Wild Dataset. This dataset contains 6666 images of varying image sizes, and each image has 68 annotated facial keypoints (10 more than the previous dataset we worked with).
1. Data Preprocessing
I used 95% of the data as training data and the other 5% as our validation set. All examples are first converted to grayscale, pixel values are scales, keypoints are converted to length/height ratios from absolute pixel values, the size of the bounding box is cleverly increased while maintaining the aspect ratio and then finally the image is croped to this enlarged bounding box and then resized to a standard size. We use the same data augmentation techniques as we used earlier and use a training set 2x its original size.




2. ResNet-18 Model
Instead of having a custom architecture with random initialization, I used a standard pretrained ResNet-18 model to get started. I changed the first and last layer of the network to make it compatible with the dimensions we're working with. Once that was done, I trained the network for 20 epochs using mean squared error as the loss, Adam as the optimizer, and 1e-3 as the learning rate for the optimizer.
| Layer | Input Shape | Parameters | Total Parameters | |
|---|---|---|---|---|
| 1 | Conv2d-1 | [1, 1, 244, 244] | 3,136 | 3,136 |
| 2 | BatchNorm2d-2 | [1, 64, 122, 122] | 128 | 128 |
| 3 | ReLU-3 | [1, 64, 122, 122] | 0 | 0 |
| 4 | MaxPool2d-4 | [1, 64, 122, 122] | 0 | 0 |
| 5 | BasicBlock-5 | [1, 64, 61, 61] | 73,984 | 73,984 |
| 6 | BasicBlock-6 | [1, 64, 61, 61] | 73,984 | 73,984 |
| 7 | BasicBlock-7 | [1, 64, 61, 61] | 230,144 | 230,144 |
| 8 | BasicBlock-8 | [1, 128, 31, 31] | 295,424 | 295,424 |
| 9 | BasicBlock-9 | [1, 128, 31, 31] | 919,040 | 919,040 |
| 10 | BasicBlock-10 | [1, 256, 16, 16] | 1,180,672 | 1,180,672 |
| 11 | BasicBlock-11 | [1, 256, 16, 16] | 3,673,088 | 3,673,088 |
| 12 | BasicBlock-12 | [1, 512, 8, 8] | 4,720,640 | 4,720,640 |
| 13 | AdaptiveAvgPool2d-13 | [1, 512, 8, 8] | 0 | 0 |
| 14 | Linear-14 | [1, 512] | 69,768 | 69,768 |
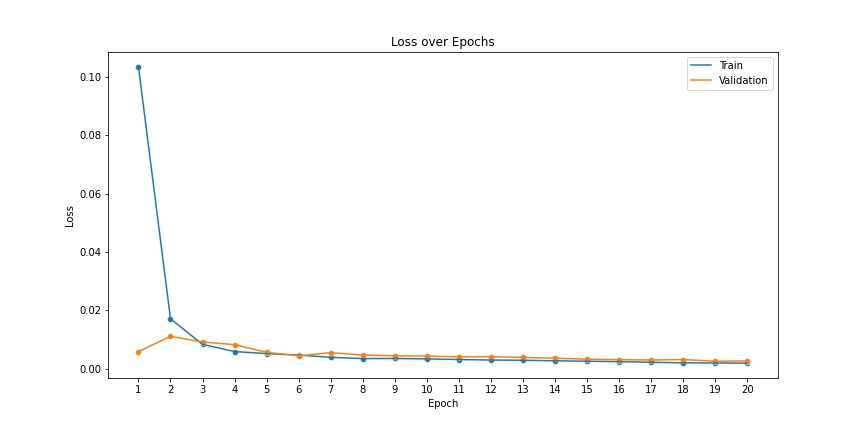
3. Results




We got a score of 15.06838 for the entire test set on Kaggle using our ResNet-18 model trained for 20 epochs using the hyperparameters specified above. Here are some more predictions.



The model seems to do decently well on two human faces it has never seen before but it fails when it comes to detecting facial keypoints in cartoons.
4. Shift-Invariant ResNet-18 Model
I tried using a Shift-Invariant ResNet-18 Model from Richard Zhang's work to compare it's performance to the standard pretrained ResNet-18 model. I trained both the models using the same hyperparameters (no optimization for either) so to have a fairer comparision. I ran both models with MSE, Adam, alpha=1e-3 for 20 epochs. In the end the standard model performed better on unseen data (Kaggle test set). The standard model's loss was 15.06838 as compared to the other model's 20.14039.
I had a couple hypotheses as to why this might have happened when intuituively we would expect our new model to perform better. The first, most reasonable hypothesis is that the model got stuck in a local minima around the 20th epoch which caused its performance to go down. This was partly supported by the validation loss of the model as well which started going up after the epoch 16. Now this could potentially imply that the model was overfitting but I don't believe that was the case here given our large diverse dataset with heavy data augmentation. Moreover, the model had the loss of 16.29837 (better) on the test set using the weights from epoch 16 instead of the ones from epoch 20 again pointing towards unlucky local minima/overfitting. The other hypothesis I had was that maybe the model actually wasn't better because we accounted for shift invariance through random shifts and rotations through our data augmentation. Given how long it took to train these models I wasn't able to further test out my theories, but I believe the new model would probably have beat the vanilla ResNet model if trained longer with hyperparameter optimization.